 We’re entering chapter 3 of my quest to provide chapter markers in the podcast. The original request was from Joe LaGreca but since I’ve started talking about it on the show, people have been coming out of the woodwork saying, “Yes, please!”
We’re entering chapter 3 of my quest to provide chapter markers in the podcast. The original request was from Joe LaGreca but since I’ve started talking about it on the show, people have been coming out of the woodwork saying, “Yes, please!”
I have been working my little fingers and brain to the bone on this and I’ve figured out a really geeky solution. But first, let’s walk through what doesn’t work.
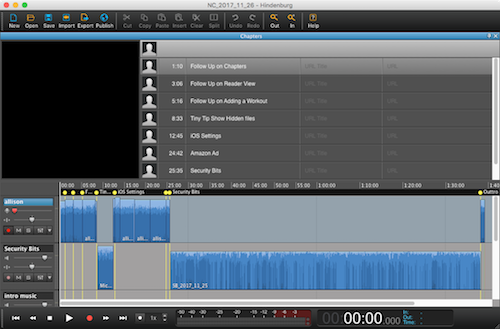
To review, I record the show in Hindenburg Journalist. I stop recording when I end each topic anyway, so it’s super easy to hit ?-control-enter to add a chapter and then type in the subject. The problem is that Hindenburg isn’t embedding those chapters on export. The dev and I have gone back and forth a few times and they seem to be saying that the chapters should be maintained, but they’re definitely not in the file.
Last week I took my exported aiff (uncompressed) file and imported it to the Auphonic service online. This subscription service levels the audio, raises or lowers the levels to the loudness standards, transcodes the file to an mp3 and embeds the ID3 tags that tell your podcatcher everything about the show. I broke down and got the subscription when I realized how many people want the chapters and how much more automated it would be on my end.
In theory, Auphonic is supposed to maintain the chapters, but since they weren’t embedded in the file as I thought they were, the show last week when first posted didn’t have chapters. After production, I was messing around in the Auphonic online tool and I noticed that you can edit a production job even after the file has been produced. In that editor, I found where I could type in the chapter markers manually.
I entered the chapter markers, had it embed them in the mp3 and downloaded again. I pushed that new version of the mp3 up to my audio hosting service, Libsyn. Anyone who’s podcatcher pulled the file a few hours after the original posting did get chapters! Michael from Germany confirmed this with delight.
Now I love you guys but I’m not typing the chapters in twice every week, there had to be a better way! Right next to where I could type the chapters in by hand was an option to upload a text file. Off to Hindenburg to figure out how to export the chapters.
 In the tool, there’s a place to upload a text file of the chapters. Not as streamlined as having them embedded in the file from Hindenburg but still better than typing twice. In Hindenburg, the chapters interface can be a hovering window or, if you drag it around, it can be across the top or side of the recording window. It’s a delightful interface. But for the life of me, I couldn’t figure out how to export as a text file. I right clicked my little fingers to the bone on the text area of the chapters, and all it would offer me was the option to export the audio of the chapter on which I was right-clicking.
In the tool, there’s a place to upload a text file of the chapters. Not as streamlined as having them embedded in the file from Hindenburg but still better than typing twice. In Hindenburg, the chapters interface can be a hovering window or, if you drag it around, it can be across the top or side of the recording window. It’s a delightful interface. But for the life of me, I couldn’t figure out how to export as a text file. I right clicked my little fingers to the bone on the text area of the chapters, and all it would offer me was the option to export the audio of the chapter on which I was right-clicking.
Back to writing to the dev. I should mention that the dev is SUPER responsive, and I think it might be a guy named Hindy, but his help files are not very good. For example, how to export chapters isn’t covered at all. Anyway, Hindy (I’ll call the dev that for simplicity) wrote back and included a screenshot of how to do the export. The chapter window has a grey bar right above the top chapter, and you’re supposed to right click on that area and then you’re given options to copy text or export as a text file. While I was delighted to know this party trick, I sure would have preferred maybe File/Export to include the chapters option. Or maybe something in the documentation about it.
Now I was really excited though. I exported my chapters as a text file and went back to Auphonic to import the file. Sadly the site rejected the file saying it wasn’t in the right format. I had to dig around quite a bit to figure out what was wrong but I cracked the code.
My file had 8 lines in it. The first 7 were chapter markers of less than one hour, and the last was greater than one hour. The less than an hour time stamps had the format of two digits for minutes, two digits for seconds and then three digits for milliseconds. The last time stamp was at just over an hour, and it had a one digit hour, followed by the same two digits for minutes, two digits for seconds and then three digits for milliseconds. Turns out that Auphonic wants two digits for hours no matter whether it’s above or below one hour. So all 8 lines fail the test.
I wrote again to Hindy and he explained that they had made the format to match another tool’s needs, but didn’t see any reason that the other tool couldn’t accept two digit hours on every line and said it should be pretty easy to fix for me. This isn’t the first time Hindy has fixed something at my request.
But in the meantime, while I wait an indeterminate amount of time for Hindy to change the format, I got the idea that maybe I could fix the file myself with some programming. Remember my post, “I want to automate all of the things” that I wrote after going to Command-D? I was very inspired by Sal Soghoian and Ray Robertson amongst others. This task didn’t seem all that hard.
I hit the googles looking for ideas, and it looked like Perl might be the right language for editing text files. I also knew from all our time in Programming By Stealth that regular expressions (aka regex) were a way to search for a pattern in a file.
Let the record show that I have never written, nor even intentionally viewed a single line of Perl. Let the record also show that while Bart did teach us about regex in Programming By Stealth, I hadn’t written any on my own.
Between Bart who loves Perl and regex, Dorothy who loves Perl and hates regex, and Helma who loves regex but hasn’t used Perl, I figured any one of them could just write this in a hot minute for me and I’d be done. But that isn’t the way we do things around here! I wanted to do it myself. So armed with no knowledge other than the right tools to use, I embarked on writing it all by myself. My goal was to have an Automator Service where I could simply right-click on a file and tell it to fix the file for me. Spoiler, I succeeded.
One of the biggest things I learned at Command-D, especially from Ray, was that most people write programs today by copying things they find that other people have written and modifying them to meet their own needs. Before Command-D this sounded like cheating, but Ray gave me the freedom to do this with my head held high.
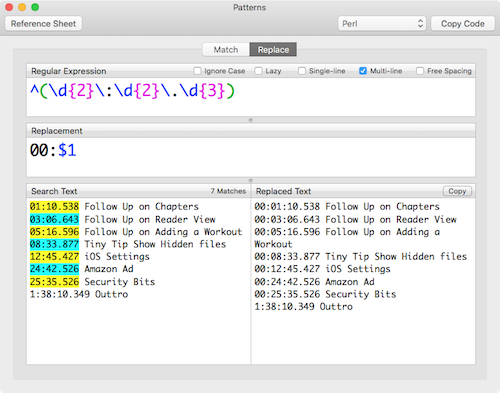 Step one was to get the regex correct to make sure I searched for the right thing in the file. I needed to separately find the lines that had no hours at all and add 00: and then find the lines with hours but no leading zero and add the zero.
Step one was to get the regex correct to make sure I searched for the right thing in the file. I needed to separately find the lines that had no hours at all and add 00: and then find the lines with hours but no leading zero and add the zero.
Regex works by a series of special characters to match patterns in the text you’re querying. In this example, I started by trying to match every instance where there are two digits followed by a colon followed by two digits followed by a period followed by a period.
To match three numerical digits, you type a backslash followed by d for numerical digit, and then the number of digits you’re looking for inside of squirrelly brackets. So to match the three-digit milliseconds, you’d type \d{3}. To find the two digit minutes and seconds, you’d match with \d{2}. Later when I’m looking for the single digit hours, you can write \d{1} but the character d alone means only one digit so adding the {1} is redundant and unnecessary.
To find a specific character, you just type the backslash followed by the specific character. So to match the colon, I can type \: and likewise, the period would be \. to find the match. To match the pattern of minute, seconds and milliseconds separated by colons, I would type:
\d{2}\:\d{2}\.\d{3}
When you build it up slowly like I just did, it’s pretty easy to follow. But even in a trivially easy example like this, at first glance, that code looks like one of my cats just walked all over my keyboard!
I used a couple of swell tools called Expressions and Patterns to help me get my regex working properly, but I’m going to save the explanation of those tools for a separate post where I’ll review their capabilities. Reading out loud how regex works is almost as bad as reading the cat on a keyboard in the shownotes so I won’t read anymore to you.
I had great fun working on getting regex working properly. I took me around 3 or 4 hours to write 2 lines of code. But it was MY code.
But when I tried to apply my regex in my Perl script to the real text file from Hindenburg, it would only fix the first line of the file. All of my google searching said, “use global!” Which I already was using. I fought with this for another day, but I could not figure out what was wrong with my code.
I really truly didn’t want to tell my tutors about the project but in a weak moment I broke down and told Helma what I was doing and she asked for a copy of my script AND the text file. I’m so glad I sent it to her because there was nothing at all wrong with my code. There was a problem in the text file itself!
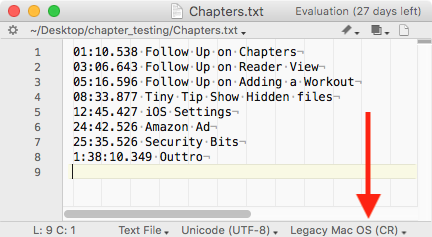 She explained to me that the text file exported from Hindenburg did not have unix line feeds at the end of each line, instead it had legacy macOS carriage returns. She discovered this by opening the file in BBEdit and looking at the bottom of the window. First of all, I didn’t even know that was a THING, and second of all, I never would have thought to look at that teeny little indicator in BBEdit, even if I had opened the file in that particular editor!
She explained to me that the text file exported from Hindenburg did not have unix line feeds at the end of each line, instead it had legacy macOS carriage returns. She discovered this by opening the file in BBEdit and looking at the bottom of the window. First of all, I didn’t even know that was a THING, and second of all, I never would have thought to look at that teeny little indicator in BBEdit, even if I had opened the file in that particular editor!
I don’t feel that it was cheating in my quest to do this all on my own, but I sure was grateful that she figured out that it was a problem in the file. I didn’t let Helma tell me how to fix this problem. Back to the googles and I found another Perl script that would swap the legacy macOS carriage returns for Unix line feeds. And it even worked!
So now I had three lines of code that when typed into the Terminal would fix the line feeds, then add the leading 00’s for hours on the lines without hours, and finally add the single leading 0 to the lines that do have hours if necessary.
I then moved over to Automator and got to work putting this into a Service. In the spirit of stealing code whenever possible and modifying it to your needs, I stole from myself. Remember the drop shadow app I wrote? That had a bash shell script inside it. I popped that Automator workflow open and stole shamelessly things like how to tell the shell I wanted to use bash, how to find the directory of the selected file and how to switch to it, and even how to assign some variables in Automator and then use them inside the script.
Of the things I did in this whole exercise, the Automator piece was by far the easiest and it only took a few iterations until I got it all working!
Now using the knowledge I’ve gained from Bart, Helma, Dorothy, and Ray, I have an Automator service that allows me to right-click on the Chapters text file and convert it to the correct format. You cannot imagine how puffed out my chest has been since I got this finished. Proud of my little self doesn’t begin to describe it.
And I think that was Bart’s goal in doing Taming the Terminal and Programming By Stealth. It was to give us the power to create. I can’t thank him enough for this.
If you’re curious to see my code, I dropped it at the end of the blog post. I’m sure it’s not the most efficient way to do it, and it may even have some edge case failures that I haven’t thought about, but it’s ALL MINE and I’m very proud of my baby. Oh, and with any luck, this week’s show will have chapter markers!
Allison’s most excellent bash script:
#!/bin/bash
# find file path and change directory to it
origName=$1
filePath=$(dirname "${origName}")
cd "$filePath"
# change legacy macos CR to unix LF
perl -p -e 's/\r/\n/g' < $1 > chapters_fixed.txt
# add leading 00: to lines without hours
perl -pi -e "s/^(\d{2}\:\d{2}\.\d{3})/00:\$1/gm" chapters_fixed.txt
# add one leading 0 to lines with hours
perl -pi -e "s/^(\d\:\d{2}\:\d{2}\.\d{3})/0\$1/gm" chapters_fixed.txt
open chapters_fixed.txt
# delete unneeded files
rm chapters_orig.txt